* [REFACTORING]Rename whitespace_tokenizer to tag_tokenizer for
registration
Name representing its purpose is preferred.
* Add lindera-tantivy to plume-model's dependencies
* Install lindera-tantivy
* Add SearchTokenizerConfig struct
* Add search tokenizers to config option
* Use CONFIG for tokenizers
* Use enum to hold tokenizer config instead of initializing on config phase
* Use guard instead of duplicate default values
* Use as_deref() instead of guard
* Move SearchTokenizer from plume-models to plume-models::search::tokenizer
* Rename SearchTokenizer to TokenizerKind
* Define SearchTokenierConfig::determine_tokenizer()
* Use determine_tokenizer in SearchTokenizerConfig::init()
* Pass tokenizer config to Searcher methods
* Add LowerCase filter to Lindera tokenizer
* Add test for Lindera tokenizer
* Define SEARCH_LANG env to specify tokenizers set
* Run cargo fmt
* Make Lindera tokenizer optional
* Fix typos
* Paginate the outbox responses. Fixes#669
* Address Ana's review
* Make outbox_fetch page through instance outboxes
* Fix infinite loop in fetch_outbox
* Fix off by one
* Begin adding support for timeline
* fix some bugs with parser
* fmt
* add error reporting for parser
* add tests for timeline query parser
* add rejection tests for parse
* begin adding support for lists
also run migration before compiling, so schema.rs is up to date
* add sqlite migration
* end adding lists
still miss tests and query integration
* cargo fmt
* try to add some tests
* Add some constraint to db, and fix list test
and refactor other tests to use begin_transaction
* add more tests for lists
* add support for lists in query executor
* add keywords for including/excluding boosts and likes
* cargo fmt
* add function to list lists used by query
will make it easier to warn users when creating timeline with unknown lists
* add lang support
* add timeline creation error message when using unexisting lists
* Update .po files
* WIP: interface for timelines
* don't use diesel for migrations
not sure how it passed the ci on the other branch
* add some tests for timeline
add an int representing the order of timelines (first one will be on
top, second just under...)
use first() instead of limit(1).get().into_iter().nth(0)
remove migrations from build artifacts as they are now compiled in
* cargo fmt
* remove timeline order
* fix tests
* add tests for timeline creation failure
* cargo fmt
* add tests for timelines
* add test for matching direct lists and keywords
* add test for language filtering
* Add a more complex test for Timeline::matches, and fix TQ::matches for TQ::Or
* Make the main crate compile + FMT
* Use the new timeline system
- Replace the old "feed" system with timelines
- Display all timelines someone can access on their home page (either their personal ones, or instance timelines)
- Remove functions that were used to get user/local/federated feed
- Add new posts to timelines
- Create a default timeline called "My feed" for everyone, and "Local feed"/"Federated feed" with timelines
@fdb-hiroshima I don't know if that's how you pictured it? If you imagined it differently I can of course make changes.
I hope I didn't forgot anything…
* Cargo fmt
* Try to fix the migration
* Fix tests
* Fix the test (for real this time ?)
* Fix the tests ? + fmt
* Use Kind::Like and Kind::Reshare when needed
* Forgot to run cargo fmt once again
* revert translations
* fix reviewed stuff
* reduce code duplication by macros
* cargo fmt
* Theming
- Custom CSS for blogs
- Custom themes for instance
- New dark theme
- UI to choose your instance theme
- Option to disable blog themes if you prefer to only have the instance theme
- UI to choose a blog theme
* send scheme as part of webfinger remote follow template
fixtsileo/microblog.pub#49
* bump webfinger to 0.4.1
* cargo fmt
* revert translations
* Use group: prefix for blog webfinger queries
* add shrinkwraprs and implement Id thru it
This also means we can automatically convert Id to String without using
.into()!
* cleanup with the help of clippy!
* cleanup with the help of cargo fmt!
* remove extra block
* Shrinkwrap Page, ContentLen and RemoteForm
* translations
* Big refactoring of the Inbox
We now have a type that routes an activity through the registered handlers
until one of them matches.
Each Actor/Activity/Object combination is represented by an implementation of AsObject
These combinations are then registered on the Inbox type, which will try to deserialize
the incoming activity in the requested types.
Advantages:
- nicer syntax: the final API is clearer and more idiomatic
- more generic: only two traits (`AsActor` and `AsObject`) instead of one for each kind of activity
- it is easier to see which activities we handle and which one we don't
* Small fixes
- Avoid panics
- Don't search for AP ID infinitely
- Code style issues
* Fix tests
* Introduce a new trait: FromId
It should be implemented for any AP object.
It allows to look for an object in database using its AP ID, or to dereference it if it was not present in database
Also moves the inbox code to plume-models to test it (and write a basic test for each activity type we handle)
* Use if let instead of match
* Don't require PlumeRocket::intl for tests
* Return early and remove a forgotten dbg!
* Add more tests to try to understand where the issues come from
* Also add a test for comment federation
* Don't check creation_date is the same for blogs
* Make user and blog federation more tolerant to errors/missing fields
* Make clippy happy
* Use the correct Accept header when dereferencing
* Fix follow approval with Mastodon
* Add spaces to characters that should not be in usernames
And validate blog names too
* Smarter dereferencing: only do it once for each actor/object
* Forgot some files
* Cargo fmt
* Delete plume_test
* Delete plume_tests
* Update get_id docs + Remove useless : Sized
* Appease cargo fmt
* Remove dbg! + Use as_ref instead of clone when possible + Use and_then instead of map when possible
* Remove .po~
* send unfollow to local instance
* read cover from update activity
* Make sure "cc" and "to" are never empty
and fix a typo in a constant name
* Cargo fmt
Also adds a parameter to `md_to_html` to only render inline elements (so that we don't have titles or images in blog descriptions). And moves the delete button for the blog on the edition page.
I still have to update the SQLite migration once others PRs with migrations will be merged.
Also, there will be a problem when you edit a blog while not owning its banner or icon: when validating they will be reset to their default values… I don't see a good solution to this until we have a better way to handle uploads with Rocket (the same is probably happening for articles btw).
And the icon/banner are not federated yet, I don't know if I should add it to this PR or if it can come after?
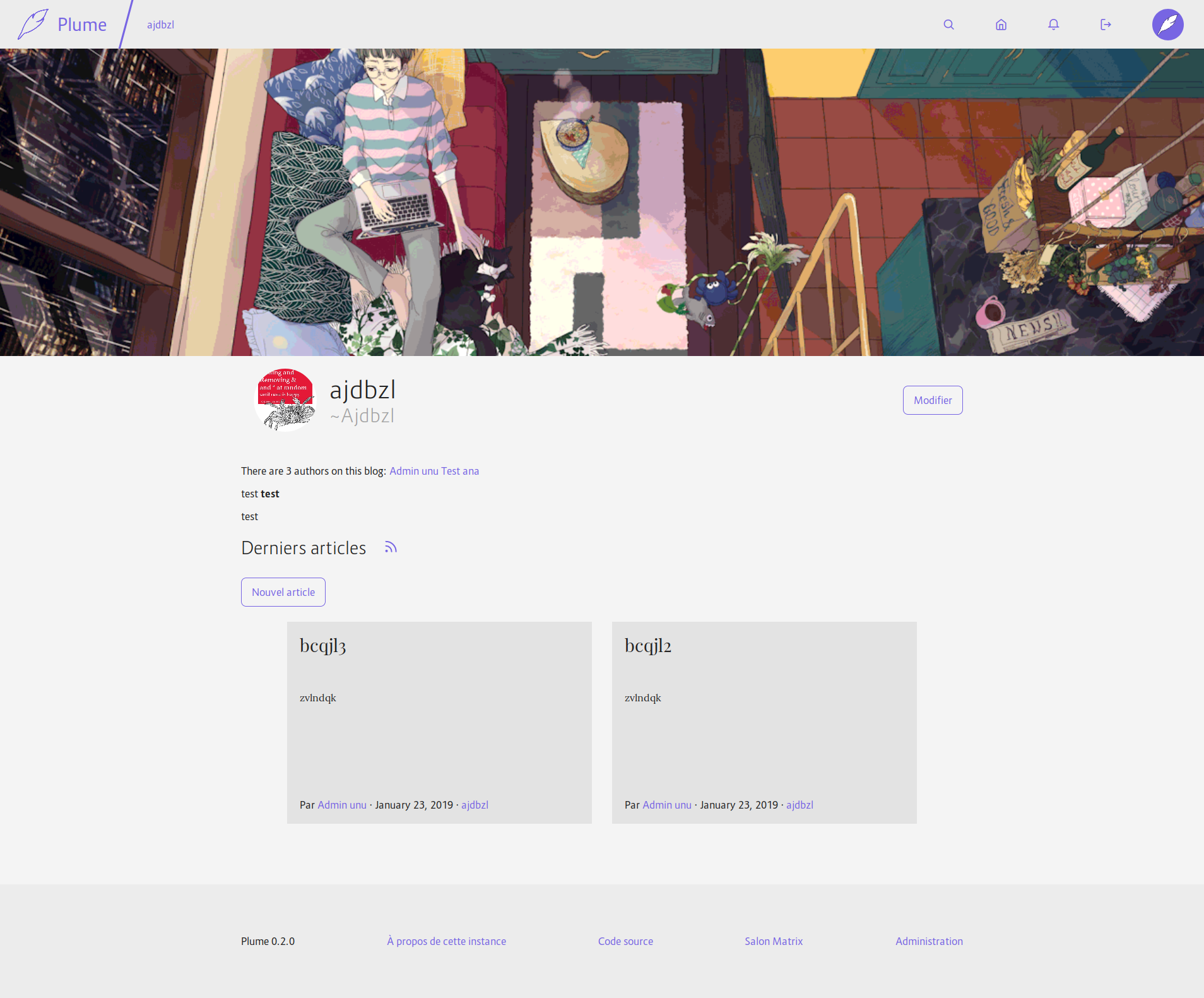
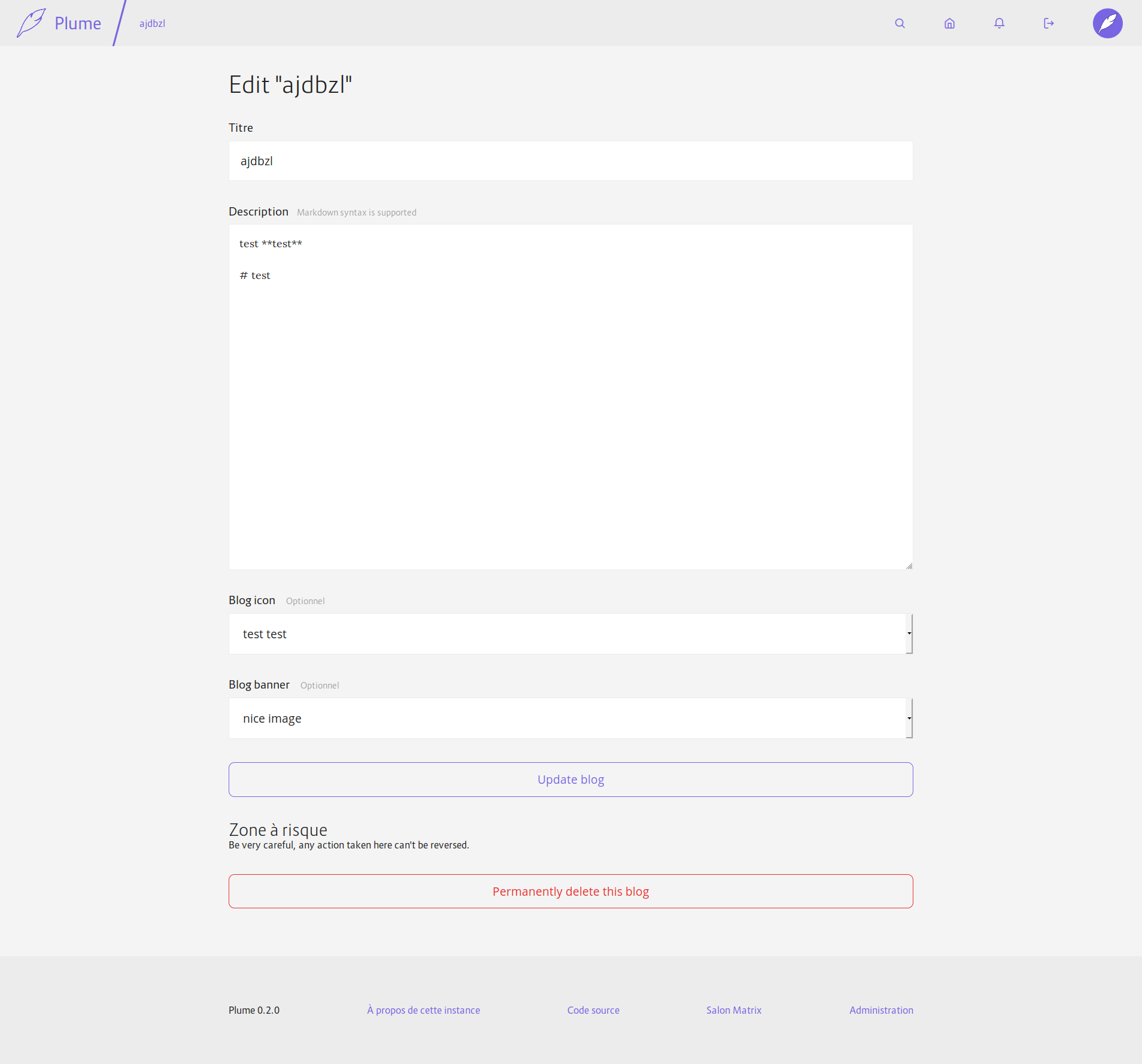
Fixes#453Fixes#454
- Use `Result` as much as possible
- Display errors instead of panicking
TODO (maybe in another PR? this one is already quite big):
- Find a way to merge Ructe/ErrorPage types, so that we can have routes returning `Result<X, ErrorPage>` instead of panicking when we have an `Error`
- Display more details about the error, to make it easier to debug
(sorry, this isn't going to be fun to review, the diff is huge, but it is always the same changes)
* Count items in database as much as possible
* Fix the tests
* Remove two useless queries
* Run pragma directive before each sqlite connection
* Pragma for tests too
* Remove debug messages
* Add some constraint at database level
Fixes#79 and should fix#201 and #113 as well
* Fix tests
Delete duplicated data before adding constraints (only with Postgres, there is no way to do it with Sqlite with complex constraints like the one we are using)
Remove the constraint on media path
* We don't need to drop the media unique constraint anymore
Because we deleted it
* Add search engine to the model
Add a Tantivy based search engine to the model
Implement most required functions for it
* Implement indexing and plm subcommands
Implement indexation on insert, update and delete
Modify func args to get the indexer where required
Add subcommand to initialize, refill and unlock search db
* Move to a new threadpool engine allowing scheduling
* Autocommit search index every half an hour
* Implement front part of search
Add default fields for search
Add new routes and templates for search and result
Implement FromFormValue for Page to reuse it on search result pagination
Add optional query parameters to paginate template's macro
Update to newer rocket_csrf, don't get csrf token on GET forms
* Handle process termination to release lock
Handle process termination
Add tests to search
* Add proper support for advanced search
Add an advanced search form to /search, in template and route
Modify Tantivy schema, add new tokenizer for some properties
Create new String query parser
Create Tantivy query AST from our own
* Split search.rs, add comment and tests
Split search.rs into multiple submodules
Add comments and tests for Query
Make user@domain be treated as one could assume
* Run cargo clippy on plume-common
Run clippy on plume-common and adjuste code accordingly
* Run cargo clippy on plume-model
Run clippy on plume-model and adjuste code accordingly
* Reduce need for allocation in plume-common
* Reduce need for allocation in plume-model
add a quick compilation failure if no database backend is enabled
* Run cargo clippy on plume-cli
* Run cargo clippy on plume
follow review from @pwoolcoc, and do not use
SafeString::new(&<String>::new())
since this makes an allocation which will then just be thrown away.
Instead, we pass ""
long_description & short_description's documentation say they can be
Markdown, but they are String, not SafeString.
This led to escaped strings being printed in the editor
https://github.com/Plume-org/Plume/issues/220
The code is divided in three crates:
- plume-common, for the ActivityPub module, and some common utils
- plume-models, for the models and database-related code
- plume, the app itself
This new organization will allow to test it more easily, but also to create other tools that only reuse a little part of
the code (for instance a Wordpress import tool, that would just use the plume-models crate)
{kind=link}
{kind=link}